以下展示传感器融合 + AI 推理的初步仿真结果,真实呈现 Stage 0 的技术能力。
Showing initial sensor fusion + AI inference simulation results — genuine Stage 0 technical capability.
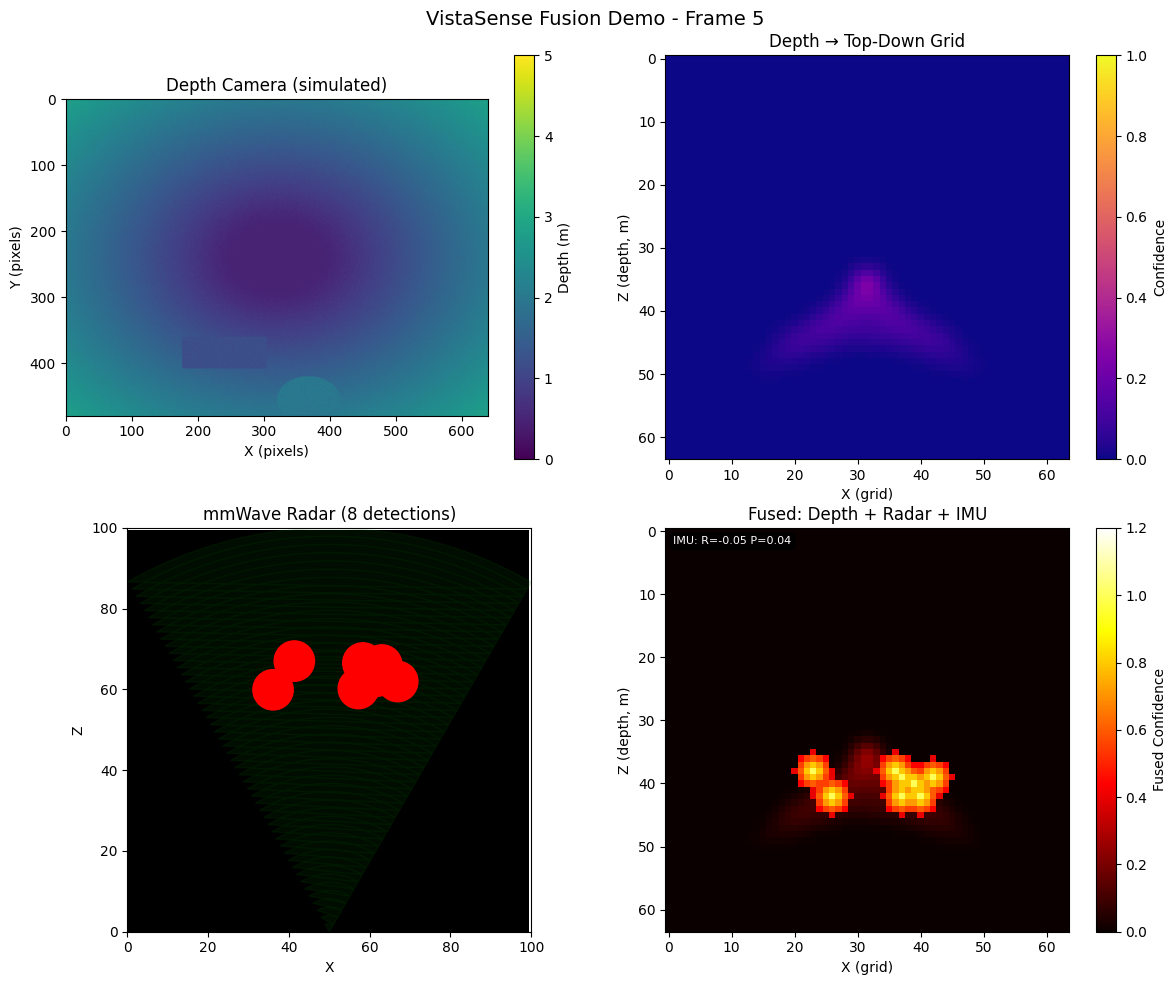
深度相机 + mmWave 雷达融合输出
Depth Camera + mmWave Radar Fusion Output
OAK-D-Lite 双目深度与 24GHz 毫米波雷达协同感知——室内环境中,即使有部分遮挡,设备仍能稳定检测人体位置与运动轨迹。
OAK-D-Lite stereo depth + 24GHz mmWave radar co-sensing — even with partial occlusion indoors, the device stably detects human position and motion trajectory.
运动轨迹实时记录
Real-time Motion Trajectory Recording
ICM20948 提供高精度姿态数据,与视觉/雷达融合,输出稳定的6-DoF运动轨迹。适合第一人称 Vlog 和 VR 拍摄的场景重建。
ICM20948 provides high-precision attitude data, fused with vision and radar, outputting stable 6-DoF motion trajectory. Ideal for first-person Vlog and VR scene reconstruction.
RK3588 实时场景理解
RK3588 Real-time Scene Understanding
6 TOPS NPU 在端侧完成 AI 推理——场景分类、物体检测、深度估计全流程实时,延迟低于 50ms。
6 TOPS NPU runs AI inference edge-side — scene classification, object detection, and depth estimation in real-time with under 50ms latency.